Detailed Function Descriptions
In This Topic...
The following sections provide detailed descriptions of certain functions.
Verifying User Security Roles
Some situations may change depending on the type of user working in the system. The following functions are used to determine if the current user has a specific security role.
For use in the policy module:
Where UserRole is the Name of the security role as it appears in the system.
For use in the claims module:
UserContainsSecurityRole(UserRole)
Where UserRole is the Code of the security role.
The functions return “True” if the user has the role, or “False” if they do not. The result can be used in a conditional formula, or as a condition within a trigger.
Compare Data Against Sanction or Watch Lists
With the potential consequences of violating international restrictions, it can be very important to validate data and ensure that it is in compliance with regulations. The Compliance() function allows one or more fields to be compared to one or more sanction or watch lists from around the world.
Comparing a Field Against a Single List
Compliance([[ScanField]],List)
Where ScanField is the field to be scanned and List is the code of the list.
Comparing a Field Against Multiple Lists
Compliance([[ScanField]],List1,List2,List3)
Where ScanField is the field to be scanned and each List# is the code of a list. Any number of lists can be included.
Comparing Multiple Fields Against Multiple Lists
Compliance([[ScanField1]] [[ScanField2]][[ScanField3]],List1,List2,List3)
Where ScanField# are the fields to be scanned and each List# is the code of a list. The scan fields are combined and scanned as one large block of text, which is why a space should be added between each field to prevent the text from flowing together.
This function outputs a numerical value from 0 (no match) to 100 (perfect match). If a different score is achieved on different lists, the highest score is returned.
See Sanction and Compliance Lists for a table of all lists and their associated codes.
Identifying When Fields Have Changed After an Integration
Transaction workflows may contain integration configurations that share data with external systems. In some cases, such as when the integration scans data for security concerns, it is important to know if the user has made changes to certain fields since the last time the integration was run.
This section describes how to assemble the necessary fields and configurations to identify such changes.
Note: It is recommended to use the DetectChanges() and ModifedOn() functions for any new configurations. See the function descriptions in the Full Function Reference List for details.
Overview:
Once configured, each time the calculated fields in a transaction are recalculated, the HashAndModifiedOn() function evaluates the tracked fields and generates a composite value derived from those fields. The first time the function runs within a transaction, it stores the composite value (the Hash value) and the current date and time.
Each time it runs after the first time, the function recalculates the composite value and compares it to the stored value. If the value has changed, the old composite value is replaced with the new value and the date and time are updated to the current date and time. Note that this stores the date and time the changes were detected by the function, and not when the changes actually occurred.
In the background, whenever an integration is completed successfully, the system stores the date and time the integration was performed. Each different integration configuration is tracked separately, so the most recent date and time information is available for each. These dates and times can be retrieved using a calculated field, providing a reference date to determine if the data was changed since the last time the integration was performed.
With the date of the integration, and the date that changes were detected in the tracked fields, the IsDateGreaterThan() function is used to compare the dates. If the tracked fields were changed after the last integration, the function returns "True". This result can be used in a trigger to re-run the integration, activate a validation, or affect any other feature that uses the trigger.
Configuration:
-
Identify and create the necessary fields.
Tip: Any of the fields used in this configuration can be hidden. Since many of the fields will only contain raw data used in the functions, it is probably best to hide them.
- Once the fields have been configured, the results can be used in triggers. The trigger conditions should check the Date Comparison Field for a true result (Field - Equals - 1) AND the Integration Flag Field should equal the value inserted by the integration.
- The triggers can then be used to reactivate the integration or for any other controls.
Interpolation/Extrapolation
The process of interpolation or extrapolation involves taking a known set of paired values, like the x and y-values of points in a grid, and determining unknown y-values from known x-values. Determining values within the known range is called interpolation, while determining values beyond the known range is called extrapolation.
The $InterpolatedLookup() function takes a lookup table already defined in the system as the known set, and will interpolate or extrapolate a value of y for a specific value of x.
The function is constructed as follows:
$InterpolatedLookup(p0,p1,p2)
P0 (text): The Code of the table containing the data. The first column of the table must be a numeric column to be used as the y-values.
P1 (text): The name of the column containing the x-values. This must be a numeric column with unique values.
P2 (numeric): The x-value for which to calculate the y-value.
The function sorts the points by the x-values in the P1 column, and then finds the two points nearest to the x-value provided as P2, shown as the dotted vertical line in the examples below. For x-values within the known range, the function finds the closest points above and below the x-value. For x-values lower than the known range, the function finds the two points with the lowest x-values, and for values higher than the range, it finds the two points with the highest x-values.
Those two points are used to determine a linear rate of increase or decrease, shown as the dashed line in the examples below.
Examples:
|
Sample Data |
|
|
X |
Y |
|
1 |
2 |
|
2 |
2.3 |
|
3 |
3.4 |
|
4 |
5 |
|
5 |
5 |
|
6 |
4 |
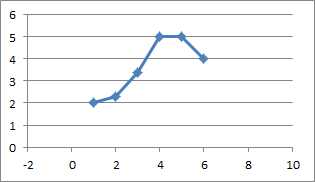
This graph shows the source data. The x-axis comes from the column identified in P1, and the y-axis comes from the first column of the table provided in P0.
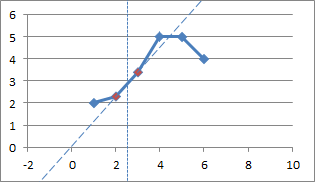
With an x-value of 2.5, the function selects the points at (2, 2.3) and (3, 3.4) as the nearest points.
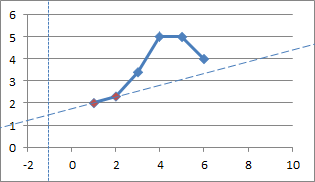
With an x-value of -1, the function selects the points at (1, 2) and (2, 2.3) as the nearest points.
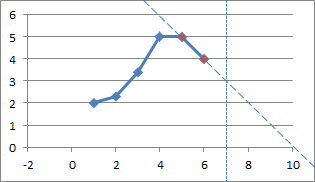
With an x-value of 7, the function selects the points at (5, 5) and (6, 4) as the nearest points.
The point where the dashed line crosses the dotted line is the interpolated or extrapolated point. The value of y at that point is determined using the following calculation.
Where (x1, y1) and (x2, y2) are the two nearest points.
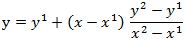
The calculated value of y is then returned by the function.
Some exceptions exist:
- If the P2 value exactly matches an x-value in the P1 column, the function returns the associated y value.
- If the table only contains one row of data, interpolation/extrapolation is not possible. The function will return the single y-value.
- If the P0 lookup table is empty, the function will return 0.
Custom Date Format Function
While there are several functions to format dates, sometimes a date needs to be presented in a very specific manner. The Custom Date Format function uses formatting codes that can be mixed and matched to provide an exceptional level of control.
The function is constructed as follows:
CustomDateFormat(Date,"{0:Code}")
Date is the date to be formatted. This can be a constant value or a placeholder. The date must be provided in the full system date format, such as "2016-06-15T14:55:22.1234-04:00". Date picker fields automatically save the date in this format.
Code is the formatting code. See the table of codes below. Some codes must be used alone, while others can be combined.
The formatting code can be pulled from a placeholder. There are two ways to achieve this.
- With the function CustomDateFormat(Date,[[CodeField]]), the Code Field must include the full {0:Code} notation. The quotes are not required within the Code Field. If the [[CodeField]] is empty, the function will not return any results.
- With the function CustomDateFormat(Date,"{0:"[[CodeField]]"}"), the Code Field only needs to contain the Code. If the [[CodeField]] is empty, the code will default to G.
Codes:
The following are pre-formatted codes that cannot be combined with other codes.
All examples are from the source date "2016-06-15T14:55:22.12-04:00".
|
Format |
Code |
Example |
Notes |
|
Date (short) |
d |
6/15/2016 |
|
|
Date (long) |
D |
Wednesday, June 15, 2016 |
|
|
Time |
t |
2:55 PM |
|
|
Time, with seconds |
T |
2:55:22 PM |
|
|
Date (short) and Time |
g |
6/15/2016 2:55 PM |
|
|
Date (short) and Time, with seconds |
G |
6/15/2016 2:55:22 PM |
|
|
Date (long) and Time |
f |
Wednesday, June 15, 2016 2:55 PM |
|
|
Date (long) and Time, with seconds |
F |
Wednesday, June 15, 2016 2:55:22 PM |
|
|
Month Name and Day |
M |
June 15 |
|
|
Month Name and Year |
Y |
June, 2016 |
|
|
Date and Time, sortable |
s |
2016-06-15T14:55:22 |
Date and time can be accurately sorted as text. |
|
Coordinated Universal Time (UTC) |
u |
2016-06-15 14:55:22Z |
|
|
RFC 1123 Format |
r |
Wed, 15 Jun 2016 14:55:22 GMT |
|
The following are component codes that can be combined to form a custom date format. Components can be divided by spaces, slashes, colons, commas, or periods.
All examples are from the source date "2016-06-15T14:55:22.12-04:00".
|
Format |
Code |
Example |
Notes |
|
Year (short) |
yy |
16 |
A single "y" can be used to show the year as either 2-digits or 1-digit without any preceding zero, but will only work when other component codes are included. |
|
Year (long) |
yyyy |
2016 |
|
|
Month (number) |
MM |
06 |
A single "M" can be used to show the month as either 2-digits or 1-digit without any preceding zero, but will only work when other component codes are included. |
|
Month (short name) |
MMM |
Jun |
|
|
Month (long name) |
MMMM |
June |
|
|
Day (number) |
dd |
15 |
A single "d" can be used to show the day as either 2-digits or 1-digit without any preceding zero, but will only work when other component codes are included. |
|
Day (short name) |
ddd |
Wed |
|
|
Day (long name) |
dddd |
Wednesday |
|
|
Hour |
hh |
02 |
A single "h" can be used to show the hour as either 2-digits or 1-digit without any preceding zero, but will only work when other component codes are included. |
|
Hour (24 hour) |
HH |
14 |
A single "H" can be used to show the hour as either 2-digits or 1-digit without any preceding zero, but will only work when other component codes are included. |
|
AM/PM |
tt |
PM |
|
|
Minutes |
mm |
55 |
A single "m" can be used to show the minutes as either 2-digits or 1-digit without any preceding zero, but will only work when other component codes are included. |
|
Seconds |
ss |
22 |
A single "s" can be used to show the seconds as either 2-digits or 1-digit without any preceding zero, but will only work when other component codes are included. |
|
Milliseconds (with trailing zeros) |
fff |
120 |
Up to seven fs can be used to show the necessary precision, with trailing zeros if the source date does not have that many digits. A single "f" can be used to show just the first digit, but will only work when other component codes are included. |
|
Milliseconds (without trailing zeros) |
FFF |
12 |
Up to seven Fs can be used to show the necessary precision, without trailing zeros if the source date does not have that many digits. A single "F" can be used to show just the first digit, but will only work when other component codes are included. |
Examples: [[SourceDate]] is "2016-06-15T14:55:22.12-04:00".
CustomDateFormat([[SourceDate]],"{0:F}")
displays
Wednesday, June 15, 2016 2:55:22 PM
CustomDateFormat([[SourceDate]],"{0:h:mm tt, dddd, MMMM dd}")
displays
2:55 PM, Wednesday, June 15
Functions to Enter Data Into Grids (Automatic Grid Processing)
While there are multiple ways to enter data into a grid, they generally require user input. Calculated fields can be used to enter data into grids, either as static values or copied from other fields or grids within the workflow. The functions can add rows, edit or replace existing rows, or clear the grid and start fresh.
The first function is ClearGrid(), which deletes all rows from a grid, as well as any associated child grids.
ClearGrid(p0)
|
Parameter 0 |
Code of the target grid. This must be a static code, not enclosed in brackets or quotes. |
The two functions for copying rows are SaveToGrid() and NewGrid(), and use the same parameters. The difference is that SaveToGrid() adds new rows after any existing rows, while NewGrid() deletes any existing rows and adds new rows to the empty grid.
SaveToGrid(p0, p1_SequenceNo, p2, p3, p4, p3, p4, …, copies, p5)
-or-
NewGrid(p0, p1_SequenceNo, p2, p3, p4, p3, p4, …, copies, p5)
|
Parameter 0 |
Code of the target grid. This must be a static code, not enclosed in brackets or quotes. |
|
Parameter 1 |
This parameter is optional, and is used in conjunction with p2 to update a single row in the target grid. The format is the Code of the target grid followed by "_SequenceNo", such as GridCode_SequenceNo. This must be a static code, not enclosed in brackets or quotes. |
|
Parameter 2 |
This parameter is optional, and is used in conjunction with p1 to update a single row in the target grid. This is the row number to be updated. This must be an integer, and can be a static value, the result of an embedded formula, or a placeholder to retrieve the value from another field. |
|
Parameter 3 |
Code of the recipient field in the target grid. This must be a static code, not enclosed in brackets or quotes. There can be multiple recipient fields, but each p3 must be followed by an associated p4 parameter. |
|
Parameter 4 |
Value to be inserted into the recipient field. This can be a static value or a placeholder to retrieve the value from another field. Each p4 must follow an associated p3 parameter. |
|
copies |
This parameter is optional and is used in conjunction with p5 to produce copies of each row as they are added to the grid. Entering the text copies indicates that copies should be created. If copies is not entered, no copies are created. |
|
Parameter 5 |
This parameter is optional and is used in conjunction with the copies parameter to indicate how many times each row should be copied as they are added to the grid. Copies are added immediately below the original row. |
Note: Without controls, the grid mapping will occur every time the calculated field is evaluated. This can result in unnecessary processing, duplicate data, or data loss if the grid is cleared after being edited.
The best way to control the processing is to isolate each function within its own calculated field, which can be hidden in the workflow. The function fields must have the Always Calculate option unchecked, or they will be activated each time the system evaluates calculated fields. Another calculated field can then be set to call the function fields from within a conditional structure.
Due to the method used to process multiple rows, the entire calculated field is re-evaluated for each row combination in the source grids, even if a conditional structure prevents the grid mapping functions from creating new rows. This can result in repetitive processing of other functions or calculations in the field. This can be avoided by moving any extra calculations to other fields that will be called before or after processing the grid mapping functions.
Basic Processing of Standalone Grids
By default, the SaveToGrid() and NewGrid() functions process every row in the source grids, and consider any child grids as separate grids. This section describes this default functionality.
For details on other options, see the Conditional Processing of Standalone Grids and Processing Parent and Child Grids sections.
If all p4 source fields are within form panels in the primary workflow, known as top-level fields, the functions create one row in the target grid.
If one or more grid fields are used as p4 source fields, the behavior depends on the configuration.
- If all grid fields are from the same grid, one new row is created in the target grid for each row in the source grid.
- If the source fields are from two or more separate grids, one new row is created in the target grid for each possible combination of the source rows. The number of new rows will equal the number of rows in the first grid, multiplied by the number of rows in the second grid, multiplied by the number of rows in the third grid, and so on. Only rows are multiplied, so taking multiple fields from a single grid will not increase the number of new rows.
- If the source fields are from a parent grid with one or more child grids, one new row is created for each parent/child/grandchild combination. Only rows are multiplied, so taking multiple fields from a single grid will not increase the number of new rows.
- If any top-level source fields are mixed in with grid sources, the value of the top-level field is repeated in each row resulting from the grid combinations. If the top-level field contains multiple values, such as a checkbox group, all selected values are combined into one value and repeated in each new row.
For example: With three grids, each with two rows, the following new rows are created.
|
Grid 1 Row 1 |
Grid 2 Row 1 |
Grid 3 Row 1 |
|
Grid 1 Row 1 |
Grid 2 Row 1 |
Grid 3 Row 2 |
|
Grid 1 Row 1 |
Grid 2 Row 2 |
Grid 3 Row 1 |
|
Grid 1 Row 1 |
Grid 2 Row 2 |
Grid 3 Row 2 |
|
Grid 1 Row 2 |
Grid 2 Row 1 |
Grid 3 Row 1 |
|
Grid 1 Row 2 |
Grid 2 Row 1 |
Grid 3 Row 2 |
|
Grid 1 Row 2 |
Grid 2 Row 2 |
Grid 3 Row 1 |
|
Grid 1 Row 2 |
Grid 2 Row 2 |
Grid 3 Row 2 |
For example: For a parent grid with one child grid, where the first row in the parent has three child rows, the second parent row has two child rows, and the third parent row has one child row, the following new rows are created.
|
Grid 1 Row 1 |
Grid 2 Row 1 |
|
Grid 1 Row 1 |
Grid 2 Row 2 |
|
Grid 1 Row 1 |
Grid 2 Row 3 |
|
Grid 1 Row 2 |
Grid 2 Row 1 |
|
Grid 1 Row 2 |
Grid 2 Row 2 |
|
Grid 1 Row 3 |
Grid 2 Row 1 |
When using p1 and p2 to update a specific row, only one value can be inserted into each field. For this reason, updates are best performed using top-level fields. To use a grid value, the formula must use a conditional structure that returns a single value from the grid.
After being evaluated, both functions return the row numbers that were added or edited.
Conditional Processing of Standalone Grids
By default, the SaveToGrid() and NewGrid() functions process every row in the source grids, and consider any child grids as separate grids. This section describes how the Where() function can be used to apply conditions that omit individual values or entire rows.
For details on other options, see the Basic Processing of Standalone Grids and Processing Parent and Child Grids sections.
Both the SaveToGrid() and NewGrid() functions can be used to copy data from specific rows in the source grid. The Where() function applies a condition that is evaluated for each row in the source grid. If the condition evaluates to True, the row or value is processed, and if it evaluates to False, the row or value is skipped. The placement of the Where() function affects the results, as shown below.
- Placing the Where() function outside of the grid function applies to the entire function, causing it to skip entire rows.
- Placing the Where() function inside the grid function applies to the preceding parameter. The grid function will process all rows, but the optional value will only be included if the condition evaluates to True.
For example, a source grid has the following data.
|
Source Grid |
||
|
Field 1 |
Field 2 |
Number |
|
Row 1 Field 1 |
Row 1 Field 2 |
5 |
|
Row 2 Field 1 |
Row 2 Field 2 |
14 |
|
Row 3 Field 1 |
Row 3 Field 2 |
9 |
|
Row 4 Field 1 |
Row 4 Field 2 |
20 |
The following formula is used.
NewGrid(TargetGrid,
TargetGridField1, [[SourceGridField1]],
TargetGridField2, [[SourceGridField2]],
TargetGridNumber, [[SourceGridNumber]])
Where([[SourceGridNumber]] > 10)
The Where() function evaluates if the value in the Number field is greater than 10, which produces the following content in the target grid.
|
Target Grid |
||
|
Field 1 |
Field 2 |
Number |
|
Row 2 Field 1 |
Row 2 Field 2 |
14 |
|
Row 4 Field 1 |
Row 4 Field 2 |
20 |
For example, a source grid has the following data.
|
Source Grid |
||
|
Field 1 |
Field 2 |
Number |
|
Row 1 Field 1 |
Row 1 Field 2 |
5 |
|
Row 2 Field 1 |
Row 2 Field 2 |
14 |
|
Row 3 Field 1 |
Row 3 Field 2 |
9 |
|
Row 4 Field 1 |
Row 4 Field 2 |
20 |
The following formula is used.
NewGrid(TargetGrid,
TargetGridField1, [[SourceGridField1]],
TargetGridField2, [[SourceGridField2]],
TargetGridNumber, [[SourceGridNumber]] Where([[SourceGridNumber]] > 10))
The Where() function evaluates if the value in the Number field is greater than 10, which produces the following content in the target grid.
|
Target Grid |
||
|
Field 1 |
Field 2 |
Number |
|
Row 1 Field 1 |
Row 1 Field 2 |
|
|
Row 2 Field 1 |
Row 2 Field 2 |
14 |
|
Row 3 Field 1 |
Row 3 Field 2 |
|
|
Row 4 Field 1 |
Row 4 Field 2 |
20 |
Note: Care should be taken when applying conditions to parameters. Using Where to omit a required parameter will result in an error. However, two versions of a required parameter can be provided with conditions that use one version or the other (do not include additional commas).
Processing Parent and Child Grids
By default, the SaveToGrid() and NewGrid() functions process every row in the source grids, and consider child grids as separate grids. This section describes how the Where() function can be used to copy grids with child grids, maintaining the associations.
For details on other options, see the Basic Processing of Standalone Grids and Conditional Processing of Standalone Grids sections.
Copying rows from a parent grid and child grid is a two-step operation. The first step copies all rows in the parent grid, assigning the row numbers in the process. The next step conditionally copies the rows in the child grid, matching the parent row number from the source grid to the parent row number in the target grid.
The functions for the parent copy and child copy should be kept in separate calculated fields, and called one after the other from a third field, such as "[[CopyParentGrid]] [[CopyChildGrid]]". If the two functions are not activated together like this, there is a chance that the parent data could be modified before the child data is copied, resulting in mismatched data.
- The Parent Copy function: The parent copy can be performed using the same basic processing or conditional processing methods detailed above. However, the row numbers must be tracked to allow the child copy function to associate the correct child grid rows to each parent.
- The Child Copy function: The child copy function is similar to the conditional processing method detailed above, except that the condition specifically uses row numbers to associate the child rows to the correct parent rows.
The [[GridCode_SequenceNo]] placeholder can be used to reference the internal row numbers in the grid. When copying all grid rows from a source grid to an empty target grid, the row numbers will match. However, if the copy is conditional or if the target grid is not empty, the row numbers will likely not match up and the child copy will associate the incorrect rows. The best practice in all cases is to add an extra field to the parent target grid, perhaps named "SourceRowNumber" or something similar, and copy the row numbers into this field along with the rest of the parent data. This extra field can be set to read-only, and hidden in the workflow.
Without the condition, the child copy would copy all rows in the source child grid for each row in the target parent grid. With the condition, the system still evaluates all rows in the source child grid for each row in the target parent grid, but leaves out any child rows that do not match the current parent.
The Where() function should be outside of the grid function, and should be formatted as shown below.
NewGrid(TargetChildGrid,
TargetChildGridField1, [[SourceChildGridField1]],
etc…)
Where([[TargetParentSourceRowNumber]]= [[SourceParent_SequenceNo]])
This compares the [[TargetParentSourceRowNumber]] copied by the parent copy function to the [[SourceParent_SequenceNo]] from the original parent grid, and only copies the child rows belonging to the current target parent row.
Example:
This example uses the following source data for one parent grid and one child grid. Note that the row numbers and parent row numbers (PR#) displayed in the fields are part of the test data to track the original values as they get copied. The actual internal SequenceNo values are displayed to the left of the tables.
|
Source Parent Grid |
|||
|
Seq. No |
Field 1 |
Field 2 |
Number |
|
1 |
Row 1 Field 1 |
Row 1 Field 2 |
5 |
|
2 |
Row 2 Field 1 |
Row 2 Field 2 |
14 |
|
3 |
Row 3 Field 1 |
Row 3 Field 2 |
9 |
|
4 |
Row 4 Field 1 |
Row 4 Field 2 |
20 |
|
Source Child Data for Source Parent Row 2 |
|||
|
Seq. No |
Field 1 |
Field 2 |
Number |
|
1 |
PR2 Row 1 Field 1 |
PR2 Row 1 Field 2 |
1 |
|
2 |
PR2 Row 2 Field 1 |
PR2 Row 2 Field 2 |
2 |
|
Source Child Data for Source Parent Row 4 |
|||
|
Seq. No |
Field 1 |
Field 2 |
Number |
|
1 |
PR4 Row 1 Field 1 |
PR4 Row 1 Field 2 |
1 |
|
2 |
PR4 Row 2 Field 1 |
PR4 Row 2 Field 2 |
2 |
The following formula is used to copy the rows from the source parent where the Number is greater than 10.
NewGrid(TargetParentGrid,
TargetParentGridField1, [[SourceParentGridField1]],
TargetParentGridField2, [[SourceParentGridField2]],
TargetParentGridNumber, [[SourceParentGridNumber]],
TargetParentGridSourceRowNumber, [[SourceParentGrid_SequenceNo]])
Where([[SourceParentGridNumber]]>10)
This produces the following rows in the target parent grid.
|
Target Parent Grid |
||||
|
Seq. No |
Field 1 |
Field 2 |
Number |
Source Row Number |
|
1 |
Row 2 Field 1 |
Row 2 Field 2 |
14 |
2 |
|
2 |
Row 4 Field 1 |
Row 4 Field 2 |
20 |
4 |
Note that the internal SequenceNo values do not match those in the source grid, but the Source Row Number values retain the correct original row numbers. This allows the child data to be associated to the correct parent rows.
Immediately after the parent grid copy is performed, the child grid copy is called. This formula is used to copy the rows from the source child where the Target Parent Grid Source Row Number matches the Source Parent Grid SequenceNo.
NewGrid(TargetChildGrid,
TargetChildGridField1, [[SourceChildGridField1]],
TargetChildGridField2, [[SourceChildGridField2]],
TargetChildGridNumber, [[SourceChildGridNumber]],
Where([[TargetParentGridSourceRowNumber]]= [[SourceParentGrid_SequenceNo]])
Note: It may seem odd to use conditional values that are not in either of the source or target child grids. However, when the system is processing data in child grids, it is automatically tracking the associated parent grid rows. This makes the parent values available for use in the conditions.
This produces the following rows in the target child grid.
|
Target Child Data for Target Parent Row 1 |
|||
|
Seq. No |
Field 1 |
Field 2 |
Number |
|
1 |
PR2 Row 1 Field 1 |
PR2 Row 1 Field 2 |
1 |
|
2 |
PR2 Row 2 Field 1 |
PR2 Row 2 Field 2 |
2 |
|
Target Child Data for Target Parent Row 2 |
|||
|
Seq. No |
Field 1 |
Field 2 |
Number |
|
1 |
PR4 Row 1 Field 1 |
PR4 Row 1 Field 2 |
1 |
|
2 |
PR4 Row 2 Field 1 |
PR4 Row 2 Field 2 |
2 |
The necessary parent rows have been copied, and the child rows have been copied and associated to the correct parents.
This example is a relatively straightforward copy process. Combined Conditions can be used in the Where() function of the child copy to only copy specific children, calculations and other functions can be inserted to modify data as it's copied, and a range of other combinations are possible.
Tip: This method can also be used when loading static data into child grids, rather than copying data from another child grid. As long as the Where clause is used to reference rows in the parent grid while saving data to the child grid, the system will automatically create the associations to the parent rows.
Inserting Additional List Data
When copying data into a grid, it may be necessary to add additional information that is not part of the source tables. The NewList function allows a series of values to be included in the formula, whether they are static values, calculated values, or data pulled from fields. These values will be included in the processing of the source grid values, and can even be managed with conditional controls.
The NewList function is formatted as follows.
NewList(p0,…)
The p0 parameters include all of the list values, separated by commas.
The function returns the values as a list, formatted for use in other functions. When used as the p4 parameter in a NewGrid or SaveToGrid function, this list will be processed as if it were another source grid.
Note: Since the list is processed as an additional source, the duplication rules for multiple grids will apply. This means that any rows from preceding grids will be repeated for each value in the list, and the entire list will be repeated for each row of any subsequent grids.
Example:
NewGrid(TargetGrid,TargetFieldA,SourceFieldA,TargetFieldB, NewList("1st Quarter","2nd Quarter"))
This function will copy all SourceFieldA rows to TargetFieldA rows, and copy "1st Quarter" to TargetFieldB for each row. It will then loop and copy all SourceFieldA rows to TargetFieldA rows, and copy "2nd Quarter" to TargetFieldB for each row.
With the source grid containing three rows with the values Value1, Value2, and Value3, the TargetGrid will look like this.
|
TargetFieldA |
TargetFieldB |
|
Value1 |
1st Quarter |
|
Value2 |
1st Quarter |
|
Value3 |
1st Quarter |
|
Value1 |
2nd Quarter |
|
Value2 |
2nd Quarter |
|
Value3 |
2nd Quarter |
Dividing String Values Into Rows
When copying large data fields into grids, it may be necessary to break the content up into smaller pieces. The BreakText function can be used to break the large string into smaller strings with a set maximum length, then copy the smaller strings into separate rows.
The BreakText function is formatted as follows.
BreakText(p0,p1)
The p0 parameter identifies the text to be split. This can be a placeholder, function, formula, or literal value.
The p1 parameter defines the maximum number of characters in the sub-strings. If the character number falls in the middle of a word, the system will move back to the nearest whitespace, such as a space, tab, or line break character. If a single word exceeds the maximum number of characters, the word will be split at the character limit.
The function returns the string pieces as a list, formatted for use in other functions. When used as the p4 parameter in a NewGrid or SaveToGrid function, this list will be processed as if it were another source grid.
Note: Since the list is processed as an additional source, the duplication rules for multiple grids will apply. This means that any rows from preceding grids will be repeated for each string piece in the list, and the entire list will be repeated for each row of any subsequent grids.
Example:
NewGrid(TargetGrid, TargetFieldA, BreakText("SourceFieldA", 12), TargetFieldB, NewList("1st Quarter", "2nd Quarter"))
This function will retrieve the text from SourceFieldA and divide it into strings of up to 12 characters, then copy those strings into TargetFieldA. The NewList function will copy "1st Quarter" to TargetFieldB for each row. It will then loop and copy the divided strings into TargetFieldA for a new set of rows, and copy "2nd Quarter" to TargetFieldB for each row.
With SourceFieldA containing the text "This is a sample sentence to be divided", the TargetGrid will look like this.
|
TargetFieldA |
TargetFieldB |
|
This is a |
1st Quarter |
|
sample |
1st Quarter |
|
sentence to |
1st Quarter |
|
be divided |
1st Quarter |
|
This is a |
2nd Quarter |
|
sample |
2nd Quarter |
|
sentence to |
2nd Quarter |
|
be divided |
2nd Quarter |
Converting Multi-Value Fields Into Rows
When copying Include Exclude List or Multi Select field data into a grid, the data is treated as a pipe-separated string by default. The ExtractItems() function can be used to divide the selected values into individual rows, which can then be processed by the grid management functions.
The ExtractItems() function is formatted as follows.
ExtractItems(p0)
The p0 parameter should be the Code of the source field, enclosed in brackets.
The function returns the selected values as a list, formatted for use in other functions. When used as the p4 parameter in a NewGrid or SaveToGrid function, this list will be processed as if it were another source grid.
Note: Since the list is processed as an additional source, the duplication rules for multiple grids will apply. This means that any rows from preceding grids will be repeated for each string piece in the list, and the entire list will be repeated for each row of any subsequent grids.
Example:
SaveToGrid(TargetGrid, TargetField, ExtractItems([[SourceField]]))
In this example, the SourceField is a multi select field with three options selected. These options have the codes Option1, Option3, and Option7.
The ExtractItems function retrieves the values from SourceField and divides them into rows, then the SaveToGrid function inserts those rows into the TargetField of the TargetGrid.
|
TargetField |
|
Option1 |
|
Option3 |
|
Option7 |
Load Transaction Data to Grids
When the option to Allow Quote Versions is enabled, alternate versions of an unbound New Business or Renewal transaction can be generated for the same policy term. All available quote options for a given transaction are displayed in the Quote Summary window, which is accessed by clicking the Quote Summary link in the Premium Widget within the submission workflow. For information about multiple quote options, see
If it is necessary to extract, display, or otherwise compare data from multiple quote versions outside of the Quote Summary window, the LoadTransactionstoGrids() function can be used. This function uses one or more source grids configured to contain quote version data, and maps this data to one or more target grids configured within the same workflow. The relationship between source grids and target grids is one to one, which is to say that an equal number of source grids and target grids must be configured.
The LoadTransactionstoGrids() function is formatted as follows.
LoadTransactionstoGrids('TransactionTypes', p0, 'TransactionStatuses', p1, 'IncludeSourceHeaders', p2, 'SourceGrids', p3, 'TargetGrids', p4)
| 'TransactionTypes' (static text) | This parameter is a label, enclosed in single quotation marks. |
| P0 (text) | This parameter specifies the Transaction Type for the quote versions to be searched. The value should be NewBusiness or Renewal. Multiple values should be pipe separated ( | ). |
| 'TransactionStatuses' (static text) | This parameter is a label, enclosed in single quotation marks. |
| P1 (text) | This parameter specifies the Transaction Status for the quote versions to be searched. The value should be Incomplete, Quoted, Referred, Bound, Declined, UnderwritingRequired, or Lost. Multiple values should be pipe separated ( | ). |
| 'IncludeSourceHeaders' (static text) | This parameter is a label, enclosed in single quotation marks. |
| P2 (text) | The boolean value of True or False should be used to specify whether the field labels are included or not. |
| 'SourceGrids' (static text) | This parameter is a label, enclosed in single quotation marks. |
| P3 (text) | The parameter contains the Code of the source grid. Multiple values should be pipe separated ( | ). |
| 'TargetGrids' (static text) | This parameter is a label, enclosed in single quotation marks. |
| P4 (text) | This parameter contains the Code of the target grid. Multiple values should be pipe separated ( | ). |
Example: LoadTransactionsToGrids('TransactionTypes', NewBusiness|Renewal, 'TransactionStatuses', Incomplete|Quoted, 'IncludeSourceHeaders', True, 'SourceGrids', SourceGrid|SourceGrid2, 'TargetGrids', TargetSourceGrid|TargetSourceGrid2)
Note: Any source grids configured for use within this function should contain a single row of data. This row should be empty if the version should not be included in the results. One way of achieving this is through the ClearGrid() function.
The same number of columns must be configured for each source grid and target grid pairing.
When a source grid meets criteria established by the specified Transaction Type and Transaction Status, the fields from the source grid data are mapped to the fields in the target grid according to sequence number. Gaps in the sequence numbers are accepted.
The source grid rows are displayed in the target grid in ascending order according to the quote version number.
If a source grid row does not contain any values, the details of that quote version will not be included in the target grid. All other results will continue to be sorted according to quote version number, skipping over the version that did not contain any values.
While all data types (text, numeric, etc.) are supported for use within the source grid, the data that is mapped to the target grid will be displayed according to the control type configured for the target grid cells. It is therefore recommended that the target grid be configured with the same Control Type as the source grid. If, however, 'IncludeSourceHeaders' is set to True, the Textbox control type should be used to suit string data.
Pivot Grid Data
When data is mapped from a source grid into a separate target grid, the basic column and row structure is maintained between both grids.
The PivotGrid() function allows the user to pivot the display of data in the final target grid. The source grid row data is presented vertically, and the source grid column data is presented horizontally.
The PivotGrid() function is formatted as follows.
PivotGrid(p0, p1)
Note: The number of columns in the target grid must be greater than or equal to the number of rows in the source grid.
Sorting Grid Data
While the grid controls in the system allow for the sorting and grouping of data, this only applies to that particular view of the data. The data stored in the system remains in its original order. Any feature that uses the data, such as document generation or functions, will see and process the data in that original order.
The SortGrid() function can be used to sort and subsort the data in a grid, either ascending or descending, changing the order of the data in the internal storage. Any generated documents or functions will then see and process the data in the defined order. This function does not alter the row numbers or row id values, so any features or functions that address specific rows by number or id will not be affected.
The syntax for the function is as follows:
SortGrid(p0, p1 sort order, p1 sort order, ...)
P0 (text): Code of the target grid. This must be a static code, not enclosed in brackets.
P1 (text): Code of the column to be sorted by. This must be a static code, not enclosed in brackets. If multiple columns are provided, the function processes them in the order that they are listed, subsorting on each subsequent column.
sort order (text, optional): An optional sort order can be specified after each column code. Enter ascending or asc for ascending order, or descending or desc for descending order. If no sort order is specified, the sort defaults to ascending. Placeholders can be used, allowing the order to be defined when the function is evaluated.
Returns (): N/A
Example: SortGrid(SortGridTargetGrid, Column3 [[SelectSortOrder]], Column1 descending, Column2)
This example goes to the SortGridTargetGrid, sorts first by column 3 in ascending order, as selected in the [[SelectSortOrder]] field, then subsorts by column 1 in descending order, then subsorts by column 2 in the default ascending order. See the before and after images below.

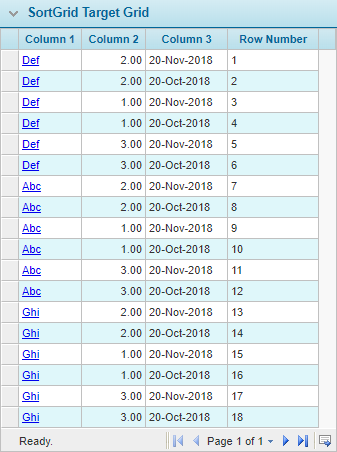
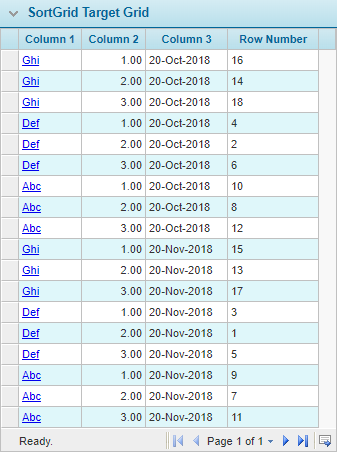
As mentioned above, the row numbers are not modified, so specific rows can still be addressed by the row number.
Searching Across Policies
In general, policy data is isolated to a single policy and its associated transactions. Documents, e-mails, and calculated fields can only access information from the current policy, plus common system information.
The Cross-Policy Data Configurations feature can be used to create a repository for data from selected fields across policies, and even across products. This data becomes available for use in calculated fields within individual transactions, and can be used to perform comparisons or searches. For information about configuring cross-policy data, see
The Cross Policy Match functions can be used in calculated fields to search for data within a cross-policy repository.
Note: The Cross Policy Match functions use the Q-gram Index search algorithm by default. To change this to the Soundex search algorithm, please contact your Insurity representative.
There are two main function types, Match and MatchList.
- The Match functions return a simple boolean value or True or False depending on whether a match is found.
- The MatchList functions return a customizable list of matching values that can be used in other functions.
For each main type of function, there are two variations.
- The ExactMatch functions only search for data that is an exact match for the provided search value.
- The FuzzyMatch functions search for data that is similar to the provided search value, within a specified tolerance range.
Cross Policy Match Functions
The two variations of the Match functions are formatted as follows.
$CrossPolicyExactMatch(p0, p1, p3, p3, p3, ...)
$CrossPolicyFuzzyMatch(p0, p1, p2, p3, p3, p3, ...)
These functions return the following values.
- $CrossPolicyExactMatch() returns "True" if an exact match is found within the stored data. Returns "False" if no match is found.
- $CrossPolicyFuzzyMatch() returns "True" if data is found that has a percentage match score that equals or exceeds the tolerance. Returns "False" if no data matches closely enough.
Examples:
$CrossPolicyExactMatch([[FieldCode]], ConfigurationCode, Product=Other, Distributor=Current, PolicyTransactionStatus=Quoted, PolicyTransactionStatus=Bound)
This function will search through the Cross-Policy Data Configuration "ConfigurationCode" for the text found in the [[FieldCode]] field. It will only search data associated to the current distributor, only within other products, and only within transactions in quoted or bound status.
$CrossPolicyFuzzyMatch([[FieldCode]], ConfigurationCode, 90, Policy=Current, Transaction=Other)
This function will search through the Cross-Policy Data Configuration "ConfigurationCode" for the text found in the [[FieldCode]] field. It will only search data associated to other transactions within the current policy. Any similar values must have a percentage match score of 90 or better to produce a positive result.
Cross Policy MatchList Functions
The two variations of the MatchList functions are formatted as follows.
$CrossPolicyExactMatchList(p0, p1, p3, return=p4|p4|…, p5)
$CrossPolicyFuzzyMatchList(p0, p1, p2, p3, return=p4|p4|…, p5)
These functions return the following values.
- $CrossPolicyExactMatchList() returns all P4 values for each transaction containing an exact match for the search value. Does not return anything if no match is found.
- $CrossPolicyFuzzyMatchList() returns the top 100 P4 values for each transaction that have a percentage match score that equals or exceeds the tolerance. The values are sorted by similarity, from highest to lowest. Does not return anything if no data matches closely enough.
Tip: The MatchList functions return multiple lists of data that are likely not useable in their default form. These functions are meant to be used within other functions capable of managing the return data. The NewGrid and SaveToGrid functions are two examples.
For the NewGrid or SaveToGrid functions, the MatchList function would be used as the P4 parameter to provide the values that will be inserted into the target fields. The P3 parameter would need to have a pipe | separated list of field codes, instead of the single field code that would normally be provided. In this configuration, there can only be one P3 and one P4 parameter, since each parameter contains all of the necessary fields.
Note that the P3 parameter must include enough fields to receive all of the data being returned by the MatchList function, otherwise an error will occur.
Examples:
$CrossPolicyExactMatchList([[SearchText]], CrossPolicySet, PolicyTransactionStatus=Quoted, Product=Other, return=FieldA | FieldB | FieldC | TransactionID, 365)
- This MatchList function will search through the Cross-Policy Data Configuration "CrossPolicySet" for the exact text found in the [[SearchText]] field.
- It will search transactions in Quoted status, belonging to products Other than the current product, that have been modified within the last 365 days.
- For each transaction containing an exact match, it will return the values of FieldA, FieldB, FieldC, and the TransactionID of the transaction.
The above MatchList function is used within a NewGrid function.
NewGrid(TargetGrid, TargetGridFieldA|TargetGridFieldB|TargetGridFieldC|TargetGridFieldD, $CrossPolicyExactMatchList([[SearchText]], CrossPolicySet, PolicyTransactionStatus=Quoted, Product=Other, return=FieldA | FieldB | FieldC | TransactionID, 365))
- Since this is the NewGrid function, the TargetGrid is cleared to prepare to receive the data.
- The P1 and P2 optional parameters are not included.
- Four pipe-separated fields are provided for P3, ready to receive the data from the three fields and transaction ID being returned by the MatchList function.
- The MatchList function itself is placed in the P4 position.
$CrossPolicyFuzzyMatchList([[SearchText]], CrossPolicySet, 85, PolicyTransactionStatus=Bound, Assured=Current, return=FieldA | FieldB | FieldC | TransactionID | Similarity, 7)
- This MatchList function will search through the Cross-Policy Data Configuration "CrossPolicySet" for text similar to that found in the [[SearchText]] field.
- It will search transactions in Bound status, belonging to the same assured as the Current transaction, that have been modified within the last 7 days.
- For each transaction containing a match score of 85% or more, it will return the values of FieldA, FieldB, FieldC, the TransactionID of the transaction, and the Similarity match score for the transaction.
The above MatchList function is used within a SaveToGrid function.
SaveToGrid(TargetGrid, TargetGridFieldA|TargetGridFieldB|TargetGridFieldC|TargetGridFieldD|TargetGridFieldE, $CrossPolicyFuzzyMatchList([[SearchText]], CrossPolicySet, 85, PolicyTransactionStatus=Bound, Assured=Current, return=FieldA | FieldB | FieldC | TransactionID | Similarity, 7))
- Since this is the SaveToGrid function, all new data will be added to any existing data in the TargetGrid. This may be done to store a history of the match searches.
- The P1 and P2 optional parameters are not included.
- Five pipe-separated fields are provided for P3, ready to receive the data from the three fields, transaction ID, and similarity score being returned by the MatchList function.
- The MatchList function itself is placed in the P4 position.